平台概览
OpenAI 兼容模式
API易 采用 OpenAI 兼容格式,跑通一次后,切换模型只需更换model 字段,其余代码完全不变:
具体可用的模型名称、定价与推荐场景,请查看下方「选择模型」中的两个专页,不在本页罗列(避免信息过期)。
功能支持范围
支持的功能
- 对话补全(Chat Completions)
- 图像 / 视频生成
- 语音转录(Whisper)
- 嵌入向量(Embeddings)
- 函数调用(Function Calling)
- 流式输出(SSE)
- 标准 OpenAI 参数:
temperature、top_p、max_tokens等 - Responses 端点
暂不支持的功能
- 微调接口(Fine-tuning)
- Files 文件管理接口
- 组织管理接口
- 计费管理接口
选择模型
不确定用哪个模型?以下两个专页保持更新,含定价、能力对比与推荐场景:文本 / 多模态模型推荐
GPT、Claude、Gemini、Grok、DeepSeek、通义、Kimi、GLM 等文本与多模态模型的能力、定价与选型建议。
图片 / 视频生成模型
Nano Banana、GPT-image、Seedream、Flux 等图像模型,以及 VEO、Sora、Wan 等视频生成模型的定价与用法。
基础信息
API 端点
- 主要端点:
https://api.apiyi.com/v1 - 备用端点:
https://vip.apiyi.com/v1
认证方式
所有请求需在 Header 中携带 API Key:请求格式
- Content-Type:
application/json - 编码:UTF-8
- 方法:大部分接口为
POST
快速开始
获取 API Key
- 访问 API易控制台 并登录
- 在令牌管理页面点击「新增」创建 API Key
- 复制生成的 Key 用于接口调用
获取多语言代码示例
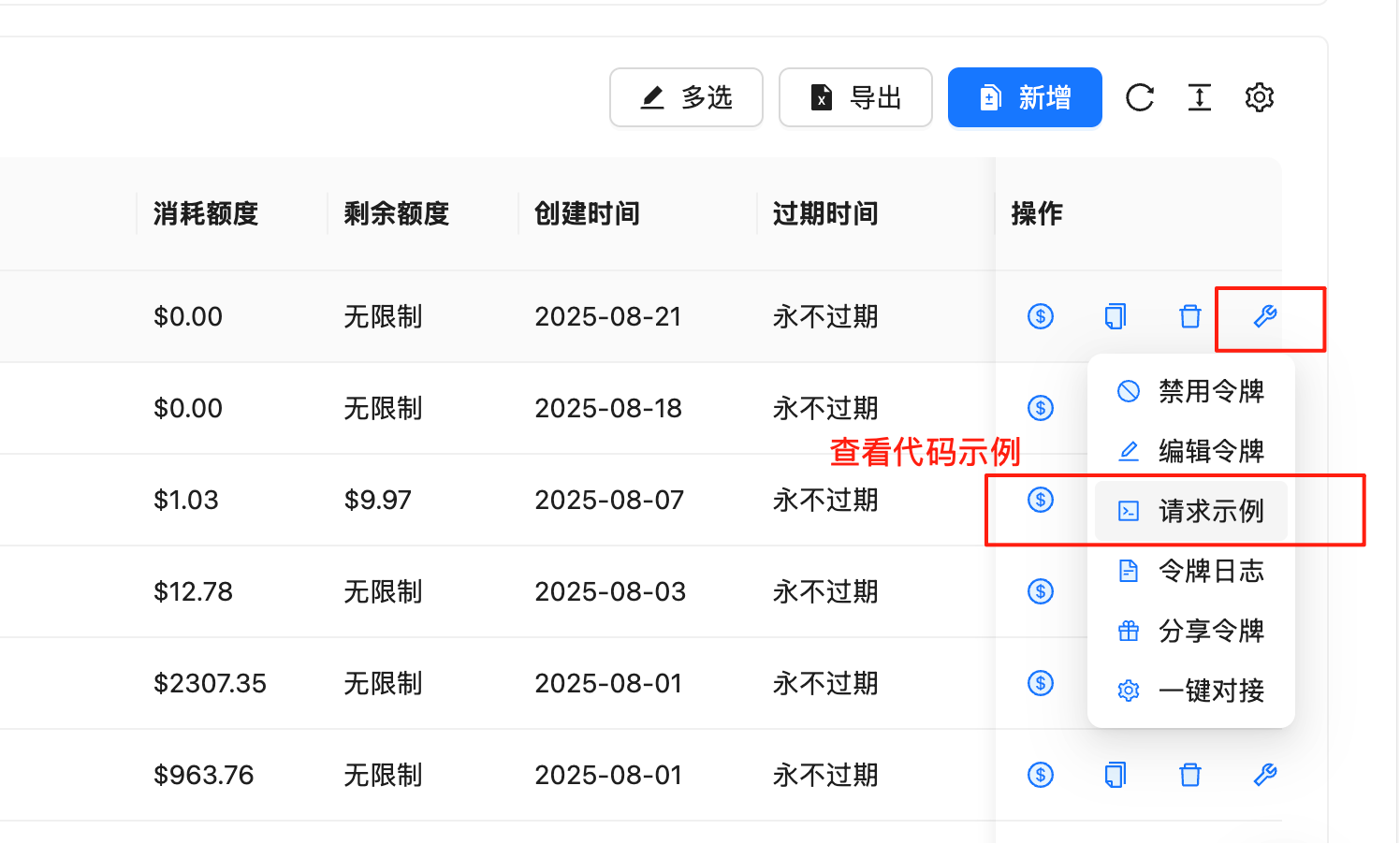
控制台已内置各语言的可运行代码示例,会随最新 API 版本实时更新,建议优先使用:- 进入 令牌管理页面
- 在目标 API Key 所在行,点击「操作」列的 🔧 小扳手图标
- 选择「请求示例」,即可查看 cURL、Python、Node.js、Java、C#、Go、PHP、Ruby 等语言的完整示例
在线调试(Playground)
「API 参考」栏目提供在线 Playground:填入 API Key 即可直接发送请求、实时查看响应,无需写代码。对话补全 Chat
POST /v1/chat/completions,对话与多模态主力接口。模型列表 Models
GET /v1/models,查询当前可用模型。向量嵌入 Embeddings
POST /v1/embeddings,文本向量化。图像、视频生成接口的 Playground 位于各自模型页(见上方「选择模型」中的图片 / 视频模型专页)。
最小调用示例
最常用的对话补全接口,复制即可运行;更多参数与语言请用上方 Playground 或控制台「请求示例」:- Python (SDK)
- cURL
流式响应
在请求中设置stream: true,响应将以 Server-Sent Events(SSE)逐块返回,适合打字机式输出:
data: 开头,最后一行为 data: [DONE] 表示结束。
错误处理
接口遵循 OpenAI 错误格式:速率限制
超出限制会返回
429,请合理控制请求频率。
需要帮助?
选择模型
文本 / 多模态模型推荐与定价。
在线调试
打开 API 参考 Playground 直接发请求。
- 访问官网:api.apiyi.com
- 技术支持邮箱:
[email protected]