Key Highlights
- OpenAI’s strongest reasoning model today — flagship reasoning variant for the hardest professional workflows; significantly higher accuracy than base GPT-5.5
- Top-tier agentic / coding scores — Terminal-Bench 2.0 82.7%, Expert-SWE 73.1%, GDPval 84.9%
- Million-token context — 1,050,000 input window, 128,000 max output
- Tiered pricing — $30 / $180 per 1M tokens for the 0–272K range; $60 / $270 for 272K–∞ (long-context 2x premium)
- SVIP group only — not exposed on the Default group to prevent misuse: a single call can cost several dollars; confirm you need it before calling
Background
On April 23, 2026 (UTC+8), OpenAI launched GPT-5.5 Pro alongside the standard GPT-5.5, with full API availability landing April 24. GPT-5.5 Pro is positioned as “OpenAI’s strongest reasoning model” — built for the toughest professional research, long-horizon code, and autonomous agent workflows. Compared with base GPT-5.5 ($5 input / $30 output), GPT-5.5 Pro’s per-token rate jumps 6× to $30 input / $180 output per 1M tokens. OpenAI’s framing: Pro spends a much larger reasoning budget and runs stricter multi-pass verification, delivering significantly higher accuracy on the hardest tasks — at exponentially higher compute cost. After a week of upstream stability monitoring, APIYI shippedgpt-5.5-pro on the OpenAI official-relay channel on May 3, 2026. Behavior and rate limits match upstream exactly. Because a single call can burn several dollars, the model is restricted to the SVIP group only — it is NOT mounted on the Default group to prevent new users from accidentally racking up charges.
Detailed Breakdown
Core Capabilities
Top agentic performance
Terminal-Bench 2.0 82.7% — sets a new high for OpenAI agentic coding
Long-horizon code chops
Expert-SWE long-horizon benchmark 73.1%, leading on cross-file multi-step tasks
Domain-expert accuracy
GDPval 84.9% across high-bar professional tasks (law, medicine, research)
Million-token context
1.05M input + 128K output — fits whole codebases or multiple long docs
Benchmarks
Source: OpenAI official model card (April 23, 2026). Benchmark results vary with eval conditions. Pro shows clear gains over base GPT-5.5 on hard tasks but the gap narrows on routine workloads.
Tech Specs
Practical Use
Recommended Scenarios
GPT-5.5 Pro’s price tag rules it out for everyday chat or routine tasks. Reserve it for high-value scenarios:- Hardest code engineering — million-line codebase audits, cross-module deadlock root-cause, Expert-SWE-style long-chain tasks
- Professional research — deep legal analysis, clinical decision support, complex financial modeling — anywhere errors are catastrophic
- Long-context synthesis — million-token cross-document comparison, contract review, patent analysis
- Autonomous agent planning — multi-step planning with self-correction in complex agent workflows
- What base GPT-5.5 can’t crack — try
gpt-5.5first; only escalate to Pro when you’ve confirmed it can’t solve the task
Code Examples
Standard call
Long-context (mind the 272K tier)
Best Practices
- Try base first — 90% of “hard” tasks are solved by
gpt-5.5; only escalate when truly stuck - Watch the context budget — keep total tokens under 272K to avoid the 2x long-context tier
- Hard budget limits in your app — enforce
max_tokensand per-user quotas to prevent runaway spend - Batch jobs use Batch API — OpenAI’s official Batch API gives 50% off (APIYI hasn’t enabled this discount channel yet)
- Not for real-time high-frequency apps — Pro responses are slower and pricier; don’t use it as a chat-bot backend
Pricing & Availability
Pricing (Tiered)
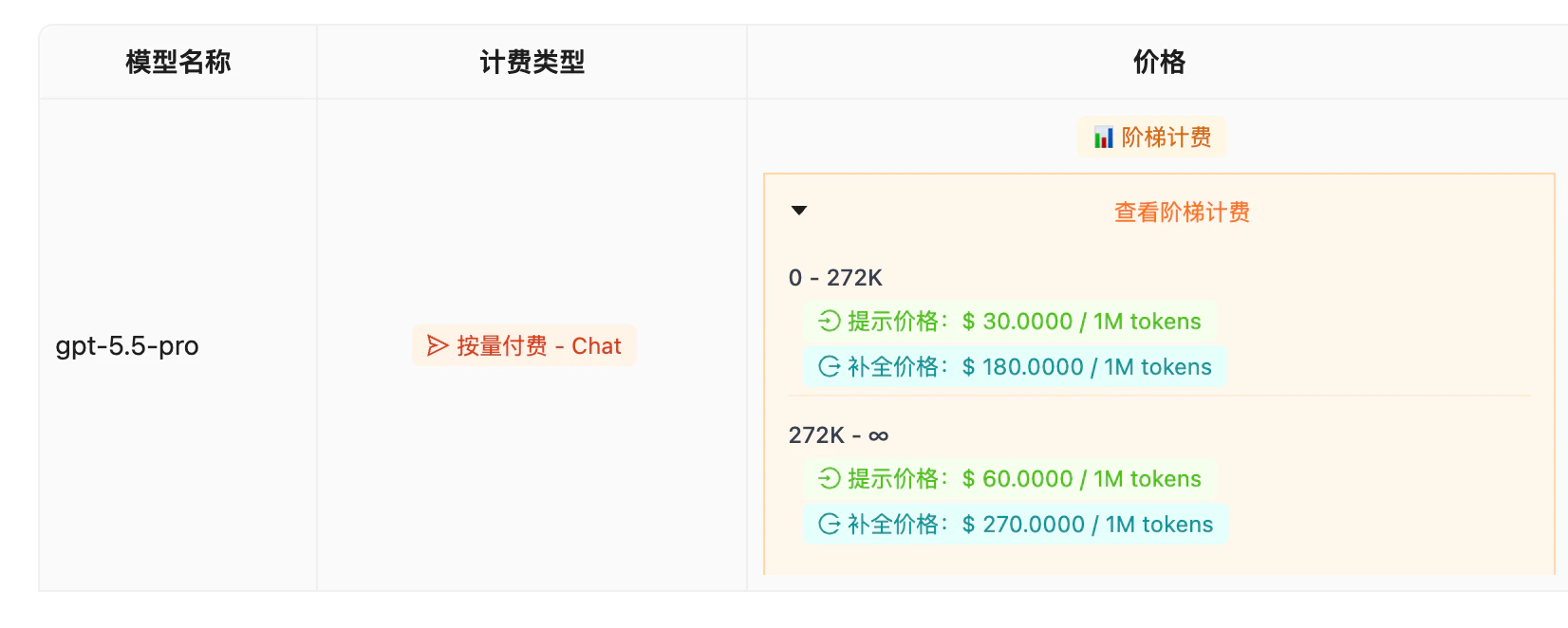
Single-call cost estimates
Price comparison with recent models
Stack with site recharge promotions
Latest recharge promotions
APIYI offers recharge bonuses; pricing matches upstream and bonuses help amortize per-call cost.
Available models & groups
For SVIP group access, contact support or check the upgrade criteria under “Group Management” in the dashboard.
Summary & Recommendations
GPT-5.5 Pro is OpenAI’s strongest — and most expensive — general reasoning model today. The value lives in accuracy ceiling on the hardest tasks: Terminal-Bench 2.0 82.7%, Expert-SWE 73.1%, GDPval 84.9% — numbers that only matter if you’re actually stuck on something hard. Worth upgrading to Pro when:- You’ve already tried base GPT-5.5 and confirmed it can’t solve the task
- Single-error cost is catastrophic (legal, medical, finance, research)
- Long-horizon code, cross-file deep refactors, complex agent workflows
- Per-call value clearly exceeds the $5–$15 cost (high-ROI scenarios)
- Routine chat, translation, summarization, code completion (GPT-5.5 or 5.4 is enough)
- High-frequency, low-latency applications (Pro is slower)
- Cost-sensitive, high-volume consumer products
Sources: OpenAI official model card (developers.openai.com), Inworld AI model library, independent benchmark coverage. Data captured: May 3, 2026 (UTC+8).