Key Highlights
- xAI’s new flagship — Grok 4.3 (April 30, 2026), positioned for “lowest hallucination rate, strongest agentic tool calling, best instruction following”
- Major price cuts — input down 37.5% and output down 58.3% vs. Grok 4.20 0309 v2; full Intelligence Index eval costs about 20% less
- Blazing fast — 159 tokens/s output, well above the 64.6 t/s median for same-tier reasoning models
- Million-token context + multimodal — 1M context window, text + image input, always-on reasoning (cannot be disabled)
- All common groups available — Default, SVIP, etc. all open; deposit $100 get 10% bonus, ~85% of xAI’s upstream pricing
Background
On April 30, 2026 (UTC+8), xAI shipped Grok 4.3 as the next flagship after Grok 4.20. The headline isn’t a benchmark sweep — it’s a cost-performance leap: a score of 53 on the Artificial Analysis Intelligence Index with the full eval suite costing only $395 to run, ~20% cheaper than Grok 4.20 0309 v2. xAI’s official positioning calls out “industry-leading non-hallucination rate, agentic tool calling, and instruction following” — three dimensions all targeted at production-grade agent workloads. On the Intelligence Index, Grok 4.3 edges past Claude Sonnet 4.6; the single biggest jump is on GDPval-AA, where ELO leapt from Grok 4.20 v2’s 1179 straight to 1500 — a 321-point one-generation gain. APIYI has shipped Grok 4.3 with all common user groups (Default, SVIP, etc.) open — pricing is friendly, blast radius is contained, no need to gate it like GPT-5.5 Pro. Stack the 10% deposit bonus and effective cost lands around 85% of xAI’s upstream rate.Detailed Breakdown
Core Capabilities
Industry-leading agent tool calling
τ²-Bench Telecom 98%, IFBench 81%; stable on complex tool chains and multi-step agents
Lowest-class hallucination rate
AA-Omniscience Accuracy +8 vs. previous; xAI claims industry-leading non-hallucination rate
Very fast output
159 tokens/s — 2.5× the 64.6 t/s median for same-tier reasoning models
Million-token context + multimodal
1M tokens context, text + image input, always-on reasoning
Benchmarks
Sources: xAI official announcement, Artificial Analysis independent benchmarks (April 30, 2026). The Intelligence Index aggregates multiple benchmarks and is a useful proxy for overall model intelligence.
Tech Specs
Practical Use
Recommended Scenarios
Grok 4.3’s combo — high speed + low price + strong agent — fits well for:- Production agent workflows — high-frequency tool calls, multi-step planning, scenarios that demand stable instruction following
- Large-scale document processing — 1M context + 159 t/s makes long-doc summarization and cross-file audits run fast
- Customer support / telecom dialogues — 98% on τ²-Bench Telecom suggests strong performance on ticketing and tech-support tool-calling tasks
- Multimodal analysis — image + text mixed input for screenshot analysis, chart reading
- Cost-sensitive high-QPS apps — low unit price + fast speed makes Grok 4.3 a reasonable substitute for GPT-5.4 / Claude Sonnet in some flows
Code Examples
Standard call
Multimodal call (image + text)
Agent tool calling
Best Practices
- Pick it for agents — τ²-Bench / IFBench data points to a clear edge in tool calling and instruction following over generic models
- Mind the 200K context tier — past 200K, input/output prices double; control prompt length on long-doc workflows
- Always-on reasoning is default — reasoning tokens count against your output bill; even simple tasks incur some reasoning spend
- Speed-first chat — 159 t/s throughput makes Grok 4.3 great for “stream-and-render” real-time chat UX
- Stack the recharge bonus — APIYI’s deposit $100 / +10% offer effectively brings cost to ~85% of upstream
Pricing & Availability
Pricing (Tiered)
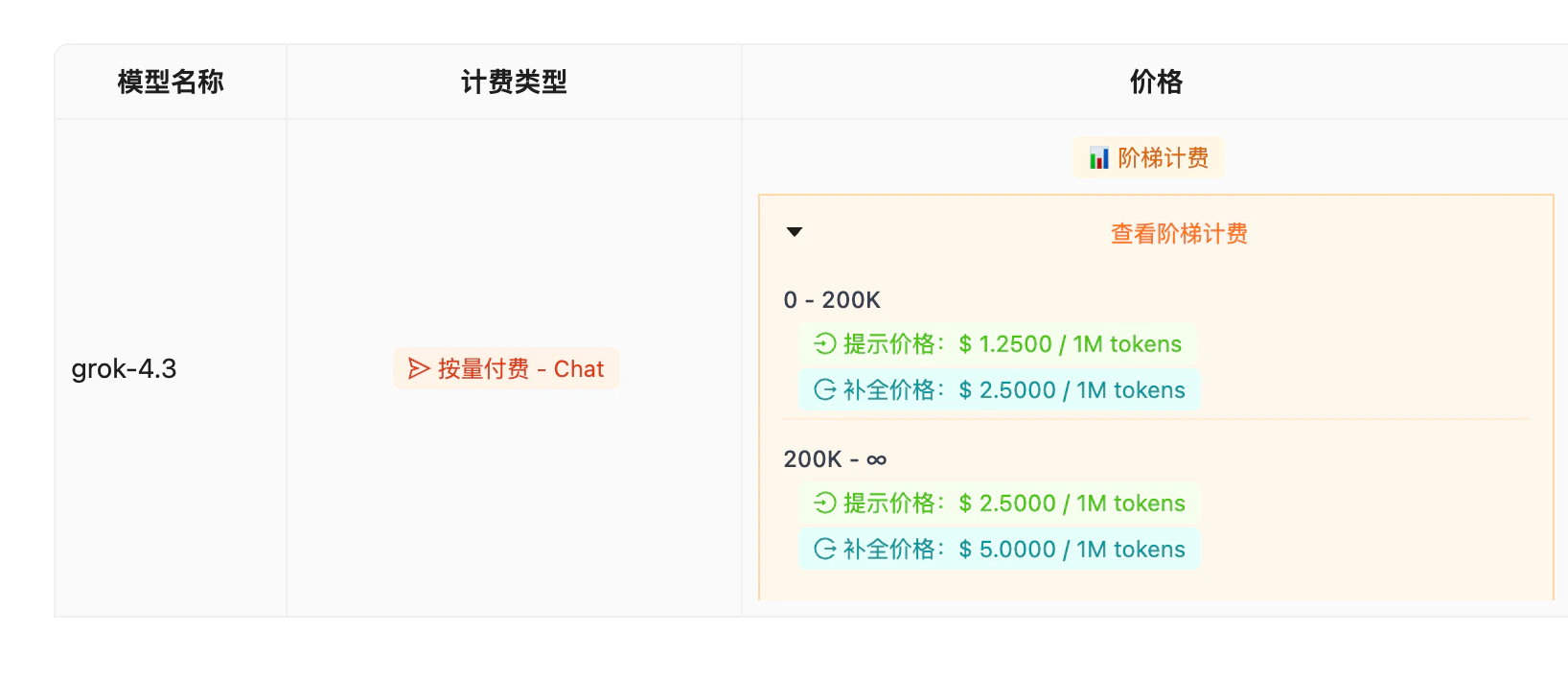
Price comparison with recent models
At $1.25 / $2.50, Grok 4.3 has essentially no same-tier rival — comparable-performance models cost 2-10× more. Cost-performance is the headline.
Stack with site recharge promotions
Deposit $100 get 10% bonus, ~85% of upstream
APIYI offers a deposit $100 / +10% bonus. Stacked on listed pricing, effective cost lands around 85% of xAI’s upstream rate — better the longer you use it.
Available models & groups
Access
- Site:
apiyi.com - API endpoint:
https://api.apiyi.com/v1 - OpenAI SDK compatible — just swap
base_url,api_key, and setmodeltogrok-4.3
Summary & Recommendations
Grok 4.3 is xAI’s most cost-effective flagship to date: $1.25 / $2.50 + 159 t/s + 1M context + strong agent skills — a combination that has essentially no competitor in the $1-3 input-price band. Worth trying / migrating to Grok 4.3 when:- You’re already running Grok 4.20 / Claude Sonnet 4.6 / GPT-5.4 mini for agent tasks — evaluate migration first
- High-frequency tool calling, customer-support automation, telecom-style ticketing
- Cost-sensitive, high-QPS real-time chat products
- Workloads needing image input multimodal analysis
- You’re already on GPT-5.5 / Claude Opus 4.7 for the hardest reasoning (Grok 4.3’s intelligence ceiling is lower)
- You depend heavily on OpenAI/Anthropic-specific API behaviors (e.g., OpenAI’s strict function schema)
- You’re stable on GPT-5.4 / Gemini 3 Pro and the migration upside is marginal
Sources: xAI official API docs (docs.x.ai), Artificial Analysis independent benchmarks, VentureBeat and The Decoder coverage. Data captured: May 3, 2026 (UTC+8).