图片 API 全部为同步调用:没有异步任务 ID,客户端断开连接结果即丢失、但请求仍会计费。请为本模型设置足够大的 timeout,详见 图片 API 调用须知与最佳实践。
概述
gpt-image-2-all 是 API易 平台上线的一款 GPT 图像生成官逆模型(逆向 ChatGPT 网页版)。以 $0.03/张 的极具竞争力的按次计费定价,约 30–60 秒出图,支持 文生图 / 单图编辑 / 多图融合 / 自然语言改图,文字还原度高、原生支持中文提示词。🎨 核心亮点:官逆通道稳定、定价统一每张 $0.03,无需关心 size/quality/n 等参数,尺寸与风格全部写进 prompt 即可——最适合”开箱即用”的图像生成场景。统一使用 OpenAI Images API 标准端点:
/v1/images/generations(文生图)与 /v1/images/edits(图片编辑)。需要锁定输出尺寸或 4K? 请改用姐妹模型 gpt-image-2-vip——调用方式与本模型完全一致,仅多一个 size 字段。文生图 API
/v1/images/generations,输入文本提示词生成图片。图片编辑 API
/v1/images/edits,multipart 上传参考图 + 编辑/融合指令。核心特性
极具竞争力定价
统一按次计费 $0.03/张,无分辨率阶梯,出图成本可预测
文字还原度高
图内中英文、招牌、海报文字还原稳定,适合信息图与营销物料
中文提示词友好
原生理解中文描述,无需翻译即可获得高质量输出
多图融合编辑
支持多张参考图同时输入,prompt 中可用「图1/图2/图3」指代
出图速度较快
约 30–60 秒出图,比
gpt-image-2-vip 和官转 gpt-image-2 都更快R2 CDN 加速返回
显式传
response_format: "url" 返回 R2 CDN 链接,全球低延迟下载自然语言改图
支持通过对话描述直接改图,无需蒙版,可多轮迭代
标准端点兼容
兼容 OpenAI Images API 标准端点
/images/generations、/images/edits模型定价
计费说明:
- 统一定价,不区分分辨率、质量或提示词长度
- 失败请求不计费(如鉴权失败、参数校验失败)
- 如需生成 N 张,客户端并行调用 N 次
分组介绍
gpt-image-2-all 放在 Default 默认分组即可,不需要额外切分组。逆向通道目前供给稳定,不存在像官转那样需要”企业分组”过渡的场景。
需要确定性 URL 输出 → 切到 image2_OSS 分组
gpt-image-2-all(及 gpt-image-2-vip)在默认分组下实测(2026-07)不传 response_format 时返回 b64_json;显式传 response_format: "url" 可拿到图片 URL。但默认分组的输出格式不做承诺——历史上曾默认返回 url、资源紧张时降级为 b64_json,行为随负载与渠道版本变化过。
如果你的业务强依赖 URL 输出(直接把 URL 落库、前端按 URL 渲染、不接受 base64),请把令牌分组切到 image2_OSS——这是专为 URL 输出确定性设计的分组,1x 倍率(不加价),对 gpt-image-2-all 和 gpt-image-2-vip 两个官逆模型都生效,保证响应稳定输出图片 URL,不会降级为 base64。
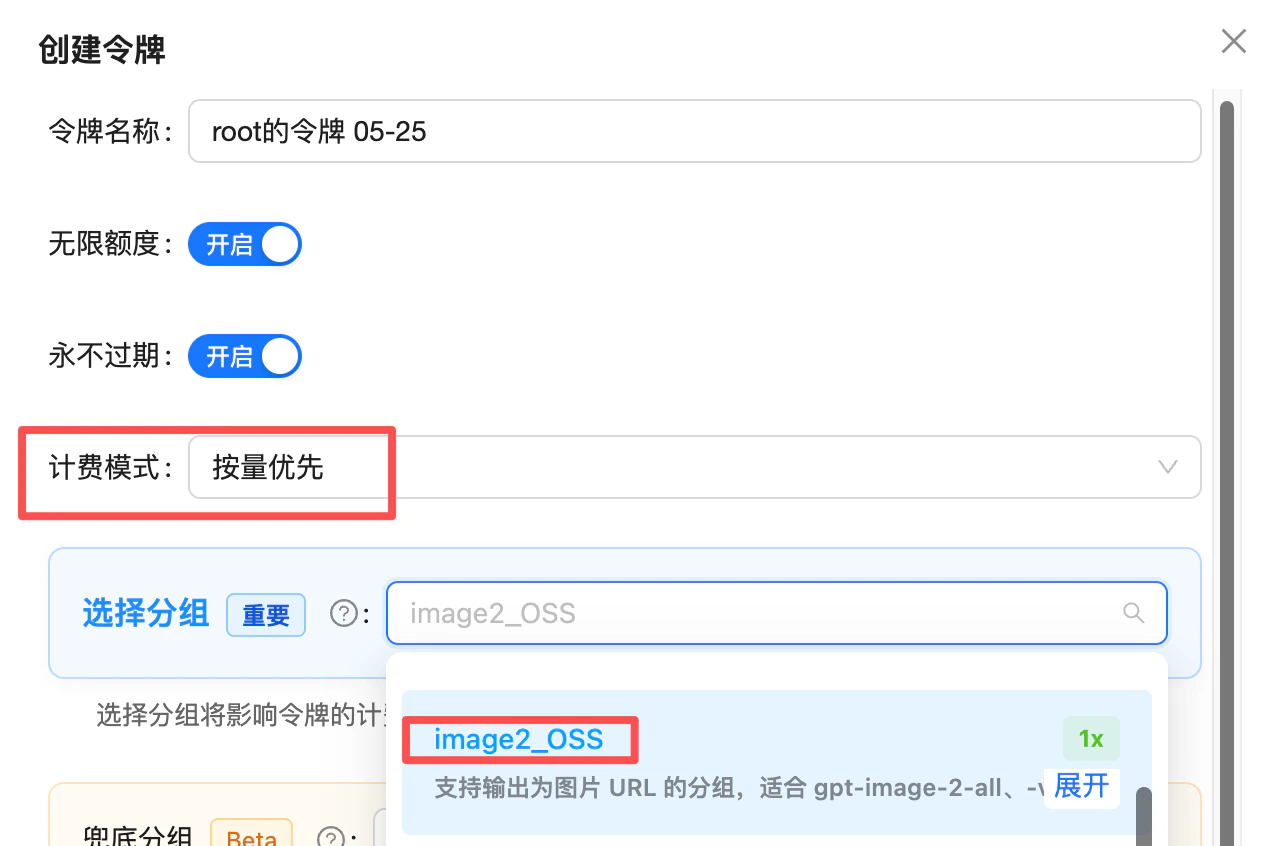
令牌创建:计费模式选「按量优先」,分组选 image2_OSS(1x)——需要确定性 URL 输出时使用
image2Enterprise 企业分组:/live/2026-04/image2-enterprise
技术规格
端点一览
想用
size 参数锁定输出尺寸? 改用姐妹模型 gpt-image-2-vip——端点完全一致,仅多一个 size 字段(30 档常见 size,含 4K)。尺寸与比例控制(写进 prompt)
gpt-image-2-all 没有 size 参数,尺寸通过 prompt 描述。如果你需要严格锁定输出尺寸(电商主图、海报模板、4K 壁纸等),请改用 gpt-image-2-vip。
经过验证的「提示词 → 实际分辨率」对照表
下表是实测复现稳定的 8 种写法。把第一列的描述放在 prompt 最前面,就能拿到第二列的分辨率(输出全部在 1.5K 像素量级):使用须知:
- 输出统一在 ~1.5K 量级(最长边 1500–2000 px),不是真正的”任意分辨率”——所有 8 种写法都属于”约 1.5K”水平的模型上限
- prompt 里只包含表中描述词时复现度最高;和其它构图词混写会发生偏离
风格化补充写法(无固定分辨率)
下面这些写法没有稳定的实测分辨率,仅作风格修饰用,搭配上表使用:把这张表暴露给终端用户
虽然gpt-image-2-all 没有 size 参数,但接入方完全可以在前端加一个「尺寸 / 比例」下拉框,给用户和官方 size 一样的体验:
- 每个选项的 value 直接用上表的 prompt 前缀(如
横版 16:9) - label 同时展示预期分辨率(如
横版 16:9 (1672×941)),让用户对最终输出有数 - 后端把选中的 prefix 拼到用户原始 prompt 的最前面再发给 API
最佳实践
1
输入图先压到 1.5MB 以内(图生图 / 多图融合)
上传给接口的每张图先压到 1.5MB 以内(JPEG 质量 80-90 / 分辨率适当下调),多图融合时也按这个标准逐张控制。偶发的服务端错误大多就是图片体积过大触发的,压一下请求成功率和出图速度都会明显改善。输出分辨率由 prompt 的画幅描述决定,与输入图体积无关——压小输入只会提速、不会损画质。提示词里光写
4K / 8K 这类词也不会真给你高清;要稳定拿到大图请用上文「经过验证的『提示词 → 实际分辨率』对照表」里的写法。2
尺寸写在 prompt 开头
把比例、分辨率、画幅描述放在提示词最前面,模型遵循度更高。
3
大胆使用文字元素
该模型文字还原度是主要卖点,招牌、海报、信息图都可直接写中英文文字。
4
多图融合标注顺序
重复传入的同名
image 字段顺序有意义,在 prompt 里可用「图1/图2/图3」明确指代。5
响应格式按需选择
Web 应用直接渲染用
b64_json,服务端中转存储用 url。6
超时设到 300 秒
典型 30–60s,但叠加图片上传 / 下载、官逆高峰长尾后实际耗时波动较大。保守按 300 秒配,避免大量误超时。
7
清理不接受的参数
gpt-image-2-all 不接受 size、n、quality、aspect_ratio,传入可能触发参数校验错误——请把它们从请求里去掉。需要传 size 时改用 gpt-image-2-vip。错误码与重试
建议客户端:
- 请求超时 300 秒 起步(保守值;典型 30–60s,但叠加图片上传 / 下载、官逆高峰长尾后波动大,按 120s 配置容易误超时)
- 对 5xx 与超时做 指数退避重试(建议 2–3 次)
- 记录响应头
request-id方便排查
常见问题
我同时看到 gpt-image-2-all 和 gpt-image-2-vip,该选哪个?
我同时看到 gpt-image-2-all 和 gpt-image-2-vip,该选哪个?
两者价格一样($0.03/次),都是逆向通道,调用方式完全一致,差异主要在
size 和出图速度:- 不需要严格控尺寸、追求出图速度 →
gpt-image-2-all(约 30–60s 出图,尺寸写进 prompt)。 - 要锁死输出尺寸或要 4K →
gpt-image-2-vip(约 90–150s 出图,30 档常见 size 含 4K)。 - 需要画质参数
quality或 OpenAI 官方完全对齐字段 → 改用官方版gpt-image-2。
能同时生成多张图吗?
能同时生成多张图吗?
本模型单次返回 1 张。如需 N 张,请客户端并行调用 N 次。每张独立按 $0.03 计费。
支持 n 参数吗?传 n=3 会怎样?
支持 n 参数吗?传 n=3 会怎样?
不支持。 本模型单次只返回 1 张图,请通过重复调用 / 并发调用的方式生成多张。⚠️ 重要:如果在请求里传入
n=3,计费会按 0.03 × 3 = $0.09 扣费,但实际上仍然只返回 1 张图。请务必把 n 字段从请求里去掉,避免被多扣费。内容被拒/模型回复「我不能做到这个需求」,会计费吗?
内容被拒/模型回复「我不能做到这个需求」,会计费吗?
官逆是同步对话式返回,结果分两种情况,计费规则不同:1) 返回 5xx 状态码 → 不计费上游内容策略明确拦截时会返回类似:这种”明确报错”调用不计费,引导用户调整提示词重试即可。2) 返回 200 状态码(模型用文字软拒绝)→ 计费模型在对话里软拒绝、用文字回复(例如「我不能做到这个需求」「抱歉,这个请求涉及……」),从协议层看就是一次正常的对话返回,这种情况会被计费。官逆目前没有办法在协议层提前识别”这一段是拒绝文字而不是图片”。为什么不能直接对软拒绝免单?强行对所有”软拒绝”都不计费意味着平台要为每次失败承担上游成本;更关键的是,频繁触发上游内容安全会让供应方账号更容易被封号——这部分供给侧的硬成本也无法完全规避。给接入方的建议
- ✅ 前置内容过滤 / 风险提示:在前端或接入层先做一道关键词与场景过滤(如真实姓名、版权角色、敏感题材),并在 UI 上提示”涉及名人/版权题材时上游限制较严,可能失败也会计费”,能显著降低误扣率。
- ✅ C 端产品月度补发:理解 C 端产品无法完全控制用户输入。如果你的月用量较大(月消费 $1000+ 起),可以按月汇总日志(短耗时调用通常对应软拒绝)联系客服一次性人工补发,无须逐条申诉。
b64_json 前缀要不要自己加 data:image/png;base64,?
b64_json 前缀要不要自己加 data:image/png;base64,?
先检测再处理。2026-07 实测返回的
b64_json 为纯 base64(不带前缀),需要解码写文件或自行拼接前缀后再渲染;但历史版本曾直接带前缀。请在代码里做 startsWith('data:') 检测:有前缀直接用作 img src,无前缀先解码,避免双重拼接或带前缀解码产出损坏的图片。为什么提示词里写了 1024x1024 还是拿到别的尺寸?
为什么提示词里写了 1024x1024 还是拿到别的尺寸?
自适应模型对尺寸描述是”参考”不是”强制”。提升遵循度的写法:把尺寸/画幅词放在 prompt 最前面,并配合画幅风格词(如
电影画幅、手机海报、方形构图)。具体能稳定复现的写法和对应分辨率,参见上文「尺寸与比例控制 → 经过验证的『提示词 → 实际分辨率』对照表」。输入图要压缩吗?提示词里写 4K / 8K 有用吗?
输入图要压缩吗?提示词里写 4K / 8K 有用吗?
强烈建议压。单张输入图压到 1.5MB 以内(JPEG 质量 80-90 / 分辨率适当下调):偶发的服务端错误大多就是图片体积过大触发的,压一下请求成功率和出图速度都会明显改善。注意 1.5MB 是推荐上限(追求稳定性与速度),上面 FAQ 写的 10MB 是网关硬上限。别担心压输入会损画质——本模型输出分辨率由 prompt 的画幅描述决定,跟你上传图的体积没关系。压小输入只会提速、不会损画质。提示词光写
4K / 8K 这类词也不会真给你高清——这些只是修饰词,模型不会因此提分辨率。要稳定拿到大图,请用上文「经过验证的『提示词 → 实际分辨率』对照表」里验证过的写法(如 电影画幅、手机海报、方形构图);需要严格锁尺寸或 4K 请改用 gpt-image-2-vip(30 档 size,含 4K,同价 $0.03/张)。参考图最大多大?格式要求?
参考图最大多大?格式要求?
推荐 单张 ≤ 10MB,格式
png / jpg / webp。过大的图可能触发网关限制。多图融合时每张都需满足此限制。生成的图片 URL 有效期是多久?需要自己转存吗?
生成的图片 URL 有效期是多久?需要自己转存吗?
url 模式响应的 url 字段是 R2 CDN 加速链接,有效期约 1 天(24 小时),过期后会 404。强烈建议:生成后尽快把图片 转存到自己的对象存储(S3 / OSS / R2)、CDN 或数据库,不要长期直接引用本服务返回的 URL。两种推荐做法:- 服务端中转:收到响应后立即
requests.get(url)把图片拉回来存到你自己的存储,把你自己的 URL 返回给前端; - 改用 b64_json:请求时加
"response_format": "b64_json",直接拿到 base64 图片数据,少一次跨域下载,适合前端直接渲染或写入文件。
能流式返回吗?
能流式返回吗?
本模型为一次性出图,不支持 stream 输出。如果对响应延迟敏感,建议客户端显示”生成中”进度提示,并合理配置 300s 超时(保守值)。
能用 OpenAI 的官方 SDK 直连吗?
能用 OpenAI 的官方 SDK 直连吗?
可以。把
base_url 指向 https://api.apiyi.com/v1,api_key 设为 API易 令牌即可。但 client.images.generate() 方法默认带 size/n 参数——本模型不接受这两个参数,建议直接用 requests / fetch 发原生 HTTP 请求调用 /v1/images/generations 与 /v1/images/edits。中文提示词和英文提示词效果差异大吗?
中文提示词和英文提示词效果差异大吗?
本模型原生支持中文,两者效果接近。对中文特有的场景(如中式书法、传统节日元素)中文表达更自然。
还能用 /v1/chat/completions 对话方式出图吗?
还能用 /v1/chat/completions 对话方式出图吗?
可以,端点仍然可用,但不再主推——推荐统一使用
/v1/images/generations 与 /v1/images/edits(更稳定、与官转 gpt-image-2 同套代码)。对话方式仅适合两类场景:多轮迭代改图、需要直接传在线图片 URL。注意出图意图不够明确时可能返回纯文字而不是图片(可在提示词开头加「生成图片:」前缀强化)。详细参数见 对话式调用说明。相关文档
- ⚖️ 官转 vs 官逆 对比 - 与官方版
gpt-image-2选型对照表 - 文生图 Playground -
/v1/images/generations兼容端点 - 图片编辑 Playground -
/v1/images/edits多图融合与改图 - GPT-Image-2-VIP(同价、支持 size 和 4K) - 同价位姐妹模型,30 档常见 size(含 4K),调用方式与本模型完全一致
- GPT-Image-2 官方版(按 token 计费) - 需要
quality参数 / mask 局部重绘 / OpenAI 官方对齐字段时的选择 - GPT-Image 系列总览 - 官方 GPT-Image 系列对比
- 社区贡献:Luck GPT-Image 2 ComfyUI 节点 - 在 ComfyUI 中一键调用
gpt-image-2-all(支持 chat_completions / images_api 双端点) - 社区贡献:APIYI GPT-Image 2 Skills - 在 Codex CLI / Cursor / Gemini CLI 等 AI 编程工具中一句话调用
- API 使用手册 - 通用调用规范
gpt-image-2-all 属于官逆通道,行为对齐但定价/能力与官方版本不完全一致。如需官方直连版本,请参考 GPT-Image-1.5。