核心要点
- OpenAI 当前最强推理:面向最复杂专业工作流的旗舰推理版本,比基础版 GPT-5.5 准确率显著更高
- 顶级 agentic / 代码评测:Terminal-Bench 2.0 82.7%、Expert-SWE 73.1%、GDPval 84.9%
- 百万级上下文:1,050,000 tokens 输入窗口、128,000 tokens 最大输出
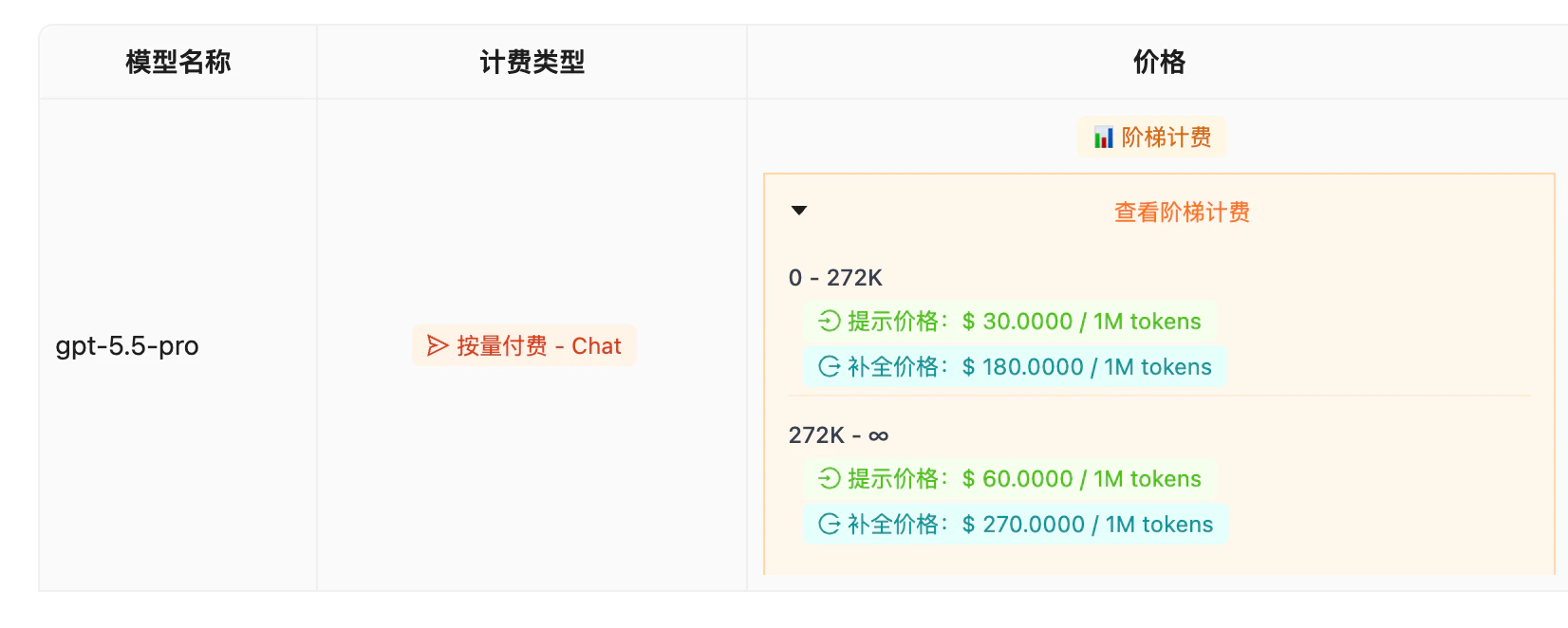
- 阶梯计费:0–272K 区间 $30 / $180 每百万 tokens;272K–∞ 区间 $60 / $270,长上下文 2x 溢价
- 仅 SVIP 分组开放:未对 Default 默认分组开放,防止误用——单次调用可能数美金,请确认场景必要性后再调
背景介绍
2026 年 4 月 23 日 (UTC+8),OpenAI 在发布 GPT-5.5 的同时推出 GPT-5.5 Pro 旗舰推理版本,4 月 24 日全面开放 API。GPT-5.5 Pro 定位为”OpenAI 当前最强推理模型”,针对最复杂的专业研究、长链代码、自主代理工作流场景。 与基础版 GPT-5.5(输入 $5、输出 $30)相比,GPT-5.5 Pro 的单价直接 翻 6 倍——输入 $30、输出 $180 / 百万 tokens。OpenAI 的解释是:Pro 版投入更高的推理预算与更严格的多次验证流程,在最难的任务上准确率显著领先,但对应的算力成本也呈指数级上升。 API易经过一周的稳定性观察后,于 2026 年 5 月 3 日正式上线gpt-5.5-pro OpenAI 官方直转通道,行为、限速与官网完全一致。考虑到该模型单次调用可能消耗数美金,仅对 SVIP 分组开放,未挂载到 Default 默认分组——避免新用户因误调用而产生意外费用。
详细解析
核心特性
顶级 agentic 表现
Terminal-Bench 2.0 82.7%,刷新 OpenAI 自家 agentic 编程纪录
长链代码能力
Expert-SWE long-horizon benchmark 73.1%,跨文件多步任务表现领先
专业领域准确率
GDPval 综合专业评测 84.9%,覆盖律师、医生、研究员等高门槛任务
百万级上下文
1.05M 输入 + 128K 输出,可吞下整个代码库或多份长文档
性能亮点
数据来源:OpenAI 官方模型卡(2026 年 4 月 23 日)。基准测试结果可能因评测条件不同而存在差异。Pro 版相比基础 GPT-5.5 在所有难任务上都有显著提升,但日常任务差距不明显。
技术规格
实际应用
推荐场景
GPT-5.5 Pro 的高单价决定了它不是日常对话或常规任务的选择,仅适合下列高价值场景:- 最难的代码工程:百万行代码库审计、跨多模块死锁定位、Expert-SWE 类长链任务
- 专业领域研究:法律深度分析、医学临床决策、金融复杂建模等容错率极低的任务
- 长上下文综合分析:百万 tokens 级别的多文档交叉对比、合同审查、专利分析
- 自主代理多步规划:需要严密推理、自我纠错的复杂 agent 工作流
- 基础版搞不定的难题:先用
gpt-5.5试跑,确认无法解决再升 Pro 版
代码示例
标准调用
长上下文场景(注意 272K 阶梯)
最佳实践
- 先用基础版兜底:90% 的”难题”用
gpt-5.5已能解决,只有真正卡住才升 Pro - 控制上下文长度:尽量保持总 tokens 在 272K 以内,避开长上下文 2x 阶梯
- 设置硬性预算上限:在自家应用层加
max_tokens与单 user 配额,防止意外烧费 - 批量任务用 Batch:如果是离线批处理,OpenAI 官方 Batch API 享 50% 折扣(API易暂未开放该折扣通道)
- 不适合实时高频场景:单次响应慢、单价高,不要拿它做 chat-bot 后端
价格与可用性
定价信息(阶梯计费)
单次调用成本估算
与近期模型价格对比
叠加网站充值活动
查看最新充值优惠政策
API易 提供充值加赠优惠,定价与官网一致,通过加赠折扣摊薄单次调用成本。
可用模型与分组
如需开通 SVIP 分组权限,请联系客服或在后台「分组管理」查看升级条件。
总结与建议
GPT-5.5 Pro 是 OpenAI 当前最强、也最贵的通用推理模型。它的价值集中在最难任务的准确率天花板——Terminal-Bench 2.0 82.7%、Expert-SWE 73.1%、GDPval 84.9% 这三个数字只对真的卡在难题上的人有意义。 适合升级 Pro 的场景:- 已经用 GPT-5.5 基础版试跑,确认仍无法解决的难题
- 对单次错误成本极高的专业领域(法律、医疗、金融、科研)
- 长链代码、跨文件多步重构、深度 agent 工作流
- 单次调用价值远高于 $5–$15 成本的高 ROI 场景
- 常规对话、翻译、摘要、代码补全(GPT-5.5 或 GPT-5.4 完全够用)
- 高频、低延迟要求的应用(Pro 响应较慢)
- 对单次成本敏感、用户量大的 to-C 产品
信息来源:OpenAI 官方模型卡(developers.openai.com)、Inworld AI 模型库、独立评测报道。数据获取时间:2026 年 5 月 3 日 (UTC+8)。