核心要点
- xAI 全新旗舰:4 月 30 日发布的 Grok 4.3,定位”幻觉率最低、Agent 工具调用最强、指令遵循最好”
- 大降价:输入价格较 Grok 4.20 0309 v2 降 37.5%、输出降 58.3%,整体跑评测预算下降约 20%
- 响应飞快:159 tokens/s 输出速度,远超同价位推理模型中位数 64.6 t/s
- 百万级上下文 + 多模态:1M tokens 上下文,文本 + 图片输入,always-on reasoning(推理常开不可关)
- 全分组可用:Default、SVIP 等常用分组均开放,充值 100 美金赠 10%,相当于官网 85 折
背景介绍
2026 年 4 月 30 日 (UTC+8),xAI 发布 Grok 4.3,作为 Grok 4.20 之后的下一代旗舰。这个版本最大的亮点不是”刷榜”,而是性价比的整体跃迁:在 Artificial Analysis Intelligence Index 上拿到 53 分,跑完一次完整评测套件成本仅 $395,比 Grok 4.20 0309 v2 低约 20%。 xAI 给出的官方定位是”业界领先的非幻觉率(non-hallucination rate)、Agent 工具调用、指令遵循”——三个维度都瞄准生产级 Agent 场景。性能上 Grok 4.3 在 Intelligence Index 综合排名上略超 Claude Sonnet 4.6,单项最大跃升发生在 GDPval-AA 评测:ELO 从 Grok 4.20 v2 的 1179 直接拉到 1500,单代提升 321 分。 API易已上线 Grok 4.3,Default、SVIP 等常用用户分组均可调用——价格亲民、风险可控,无需像 GPT-5.5 Pro 那样限制分组。叠加充值加赠 10% 后,综合成本约官网 85 折。详细解析
核心特性
Agent 工具调用业界领先
τ²-Bench Telecom 达 98%,IFBench 81%,复杂工具链与多步代理任务表现稳定
幻觉率最低之一
AA-Omniscience Accuracy 较上代 +8 分,xAI 自评”非幻觉率”业界领先
速度极快
159 tokens/s 输出,是同价位推理模型中位数(64.6 t/s)的 2.5 倍
百万上下文 + 多模态
1M tokens 上下文窗口,支持文本 + 图片输入,Always-on Reasoning
性能亮点
数据来源:xAI 官方公告、Artificial Analysis 独立评测(2026 年 4 月 30 日)。Intelligence Index 综合多项基准,可作为模型综合智能的参考指标。
技术规格
实际应用
推荐场景
Grok 4.3 的”高速 + 低价 + 强 Agent”组合特别适合:- 生产级 Agent 工作流:高频工具调用、多步规划、需要稳定指令遵循的场景
- 大规模文档处理:1M 上下文 + 159 t/s 速度,长文档摘要、跨文件审计跑得快
- 客服 / Telecom 类对话:τ²-Bench Telecom 98% 表明在工单、技术问答类工具调用任务上表现强
- 多模态分析:图片 + 文本混合输入,适合截图分析、图表解读
- 成本敏感的高 QPS 应用:单价低 + 速度快,用 Grok 4.3 替代部分 GPT-5.4 / Claude Sonnet 场景可显著降本
代码示例
标准调用
多模态调用(图片 + 文本)
Agent 工具调用
最佳实践
- Agent 场景首选:τ²-Bench / IFBench 数据显示 Grok 4.3 在工具调用、指令遵循上有明显优势,比通用模型更适合 Agent
- 关注 200K 上下文阶梯:超过 200K 后 input/output 单价翻倍,长文档场景注意控制传入长度
- always-on reasoning 是默认行为:推理 token 计入输出账单,简单任务也会有少量推理消耗
- 速度优先的对话场景:159 t/s 的吞吐让 Grok 4.3 适合”边生成边渲染”的实时聊天
- 充值加赠摊薄成本:API易充值 100 美金赠 10%,叠加挂牌价相当于官网 85 折
价格与可用性
定价信息(阶梯计费)
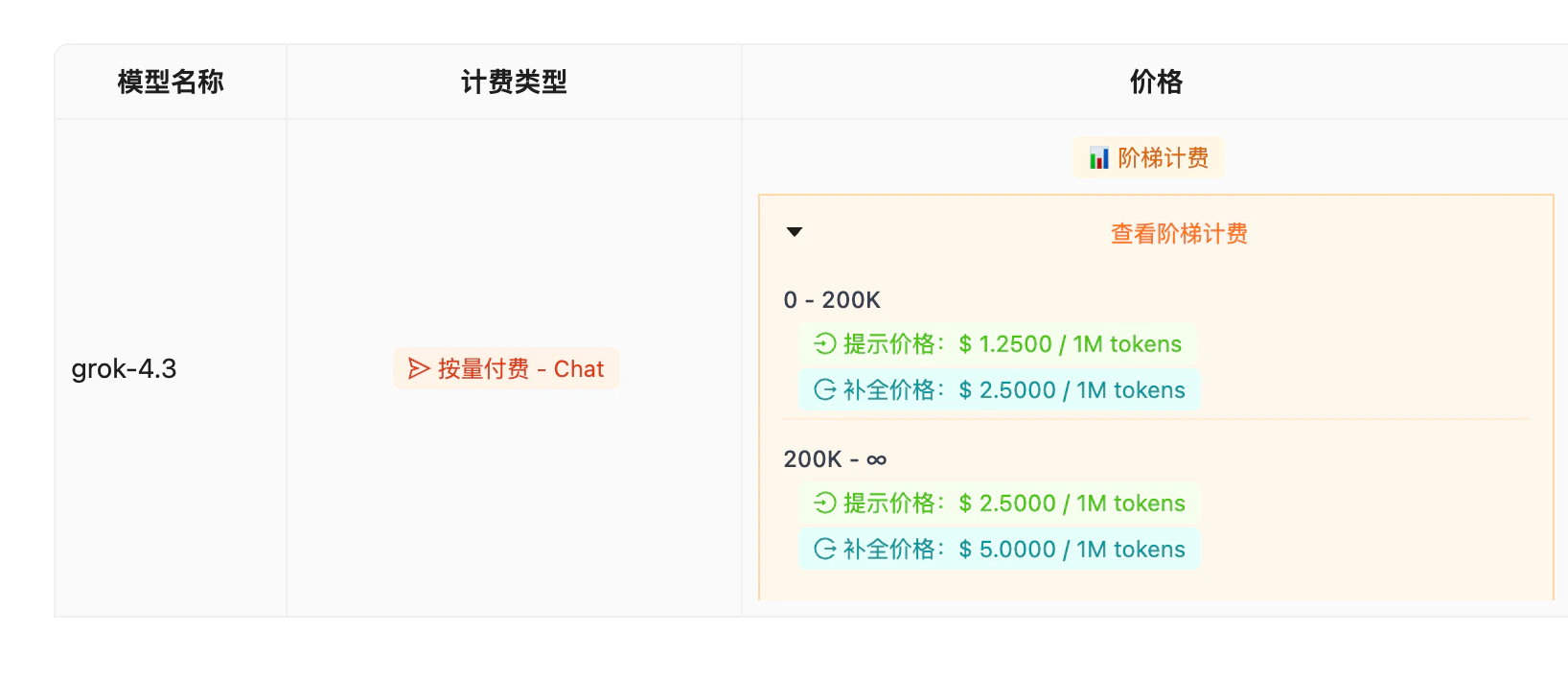
与近期模型价格对比
Grok 4.3 在 $1.25/$2.50 的价位段几乎没有同档对手——同性能模型基本都贵 2-10 倍。性价比是当前最大卖点。
叠加网站充值活动
充值 100 美金赠 10%,约官网 85 折
API易 提供充值加赠优惠:充 $100 赠 10%,叠加挂牌价后综合成本相当于 xAI 官网约 85 折,长期使用更划算。
可用模型与分组
购买渠道
- 官网:
apiyi.com - API 端点:
https://api.apiyi.com/v1 - 兼容 OpenAI 原生 SDK,仅需替换
base_url与api_key、model改为grok-4.3
总结与建议
Grok 4.3 是 xAI 当前最有性价比的旗舰:$1.25 / $2.50 + 159 t/s + 1M 上下文 + 强 Agent 能力,这套组合在 $1-3 输入价位段几乎找不到对手。 适合升级 / 切换到 Grok 4.3 的场景:- 已经在用 Grok 4.20 / Claude Sonnet 4.6 / GPT-5.4 mini 做 Agent 类任务,可优先评估迁移
- 高频工具调用、客服自动化、Telecom 类工单处理
- 成本敏感、QPS 要求高的实时对话产品
- 需要图片输入的多模态分析
- 已在使用 GPT-5.5 / Claude Opus 4.7 做最难推理任务(Grok 4.3 智能上限相对较低)
- 强依赖 OpenAI / Anthropic 特定 API 能力(如 OpenAI 函数 schema 严格行为)
- 已稳定用 GPT-5.4 / Gemini 3 Pro 跑业务,迁移收益不明显
信息来源:xAI 官方 API 文档(docs.x.ai)、Artificial Analysis 独立评测、VentureBeat 与 The Decoder 报道。数据获取时间:2026 年 5 月 3 日 (UTC+8)。